Jun 10, 2026 · 14 min read
DECISION TREES
Intuitive, visual, and highly explainable models that split data using simple if/then rules. Learn how decision trees work, why businesses love them, their overfitting problem, and how they become the foundation of Random Forests and gradient boosting.
Decision Trees are the most human-friendly machine learning models ever invented.
They make predictions by asking a series of simple yes/no questions — exactly the way most people reason about the world. Because the logic is transparent, trees are one of the few models that non-technical stakeholders will actually trust and use.
How a Decision Tree Makes Decisions
At the root, the tree looks at the entire dataset and asks: “Which single question splits the data so that the two resulting groups are as pure (similar) as possible?”
It repeats the process on each subgroup until it reaches a stopping point or the groups are pure.
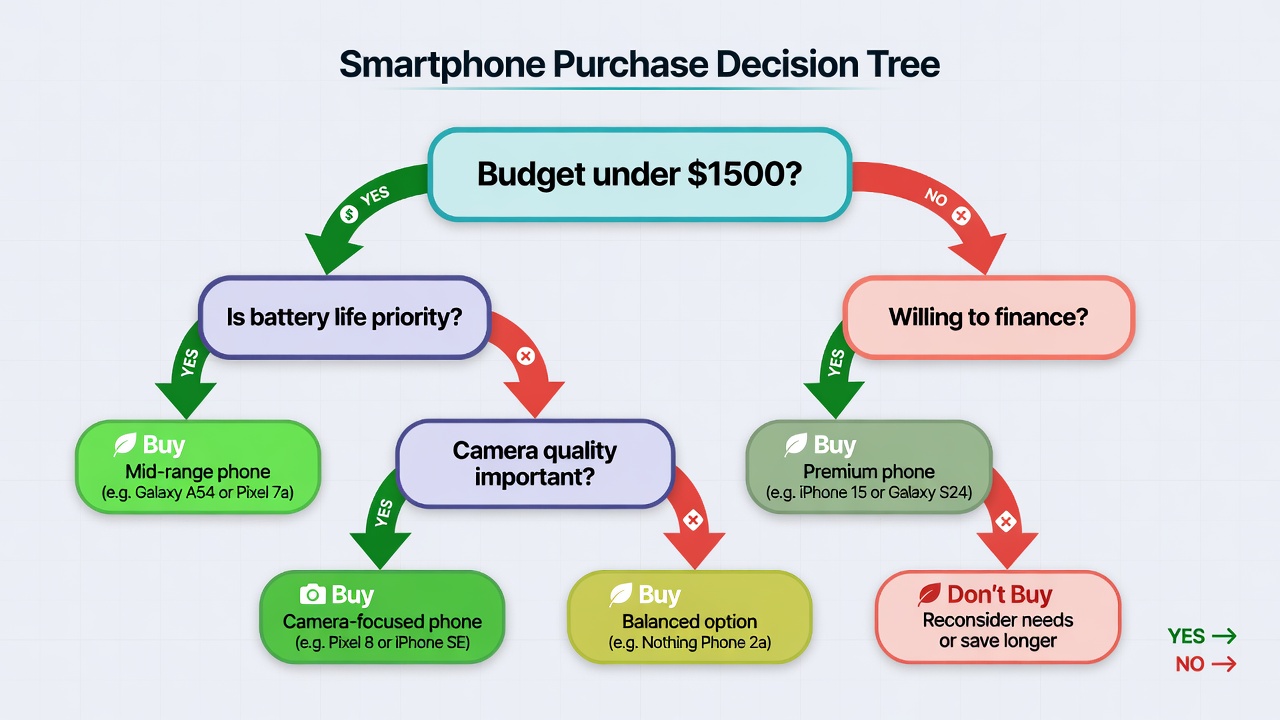
Root node asks the most important question. Each branch leads to a decision node or a final leaf (the prediction). Every path from root to leaf is a complete, human-readable rule.
The beauty is that you can print the tree and literally read the logic: “If credit score > 720 and debt-to-income < 0.35 → Approve”.
Watch: Decision Trees Explained with Animations
VIDEO — STATQUEST (JOSH STARMER)
The single best visual explanation of how trees grow, why they overfit, and what “Gini” and “information gain” actually mean in practice.
Why Businesses and Regulators Love Trees
- Full interpretability — You can show a regulator or a customer the exact sequence of decisions.
- Handles mixed data — Numbers and categories in the same model with almost no preprocessing.
- No assumptions about linear relationships or normal distributions.
- Feature importance comes for free — the tree naturally ranks which variables mattered most.
This is why decision trees (or their ensemble descendants) are still heavily used in credit risk, fraud, insurance, healthcare triage, and any domain where “why did we decide this?” is a legal or business requirement.
The Overfitting Problem (and the Solution)
A single decision tree can grow until every leaf is pure. On the training data it looks perfect. On new data it often collapses.
This is the central weakness of trees.
The solution the industry converged on is ensembles:
- Random Forest — Build hundreds of trees on different random subsets of data and features, then average their votes.
- Gradient Boosting (XGBoost, LightGBM, CatBoost) — Build trees sequentially, each one correcting the mistakes of the previous ensemble.
Almost every winning Kaggle solution and most production tree-based systems today are ensembles, not single trees.
Visual: How Purity Guides Splitting
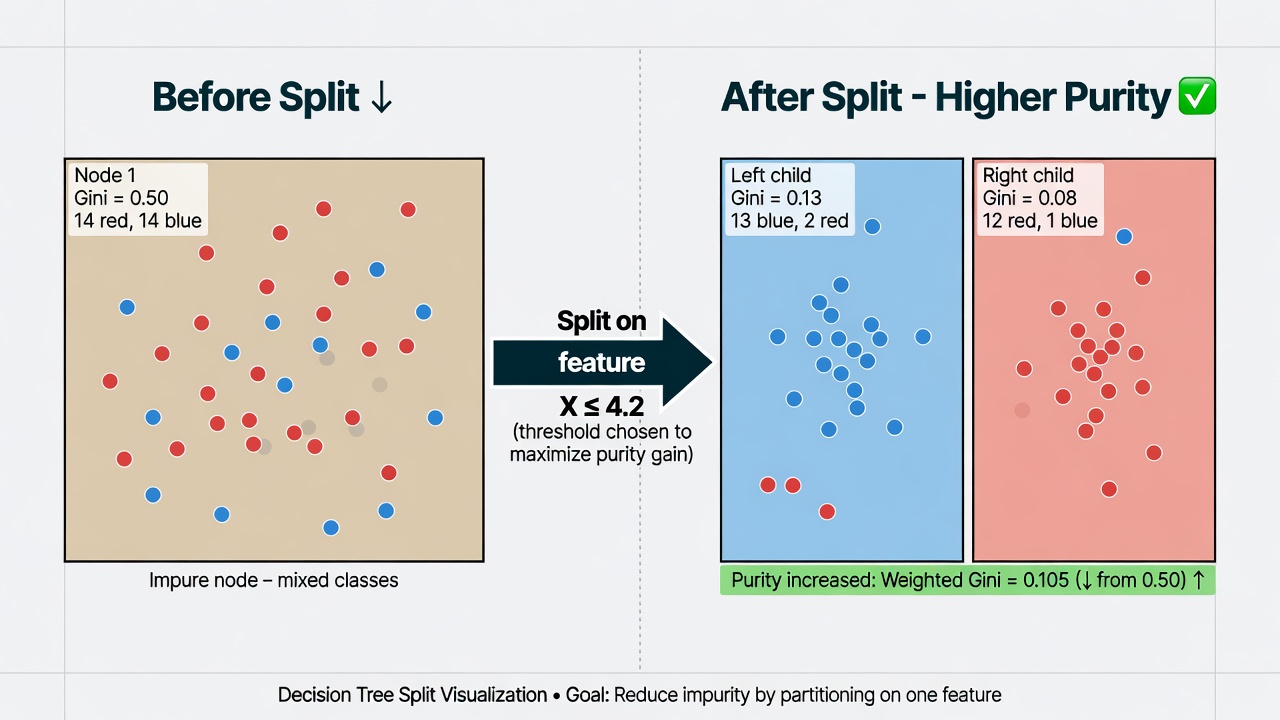
Before the split the node is mixed (50/50). After asking the right question the left child is almost pure “Yes”, the right child is mostly “No”. The algorithm searches for the question that creates the biggest purity jump.
When to Use Decision Trees (or Their Ensembles)
Use when:
- You need to explain every prediction to humans
- Your data contains important non-linear relationships and interactions
- You have a mix of numeric and categorical features
- You want built-in feature importance and robustness to outliers
Be careful when:
- You need the absolute highest possible accuracy on unstructured data (images, text, audio) — neural nets usually win
- You have extremely high-dimensional sparse data
- Interpretability is not required and you want the simplest possible model (then linear regression may be better)
Pro Tip: Start with a Shallow Tree for Understanding
Before you train a 500-tree Random Forest, fit a single shallow decision tree (max_depth=3 or 4) on the same data.
Print it. Read every path out loud.
You will almost always discover something important about how your features interact that no coefficient table or SHAP plot would have revealed as clearly.
That insight is often more valuable than the final model’s accuracy number.
Next Steps
- Master the full set: 5 Essential Machine Learning Algorithms Explained Simply
- Build one in practice: Building Your First ML Model
- See the bigger picture: Machine Learning Concepts
Decision trees are the bridge between pure statistics and human decision making. They remain one of the most important ideas in applied machine learning.
Part of the knowledge graph at The Best Blog Ever — reference definitions for ideas that matter.
Related Concepts
Related Analysis